
Imagine you have hired the smartest junior employee you can find. They are quick, eager, well-read, and they cost almost nothing per hour. You give them a task that has twenty steps, and at each step they get it right ninety-five percent of the time, which sounds excellent.
The math says they will get the whole task right thirty-six percent of the time.
You will most likely see a similar pattern when you are building applications with current LLMs. More often than not, the model is not the broken part, and the ecosystem around it is where the failures actually live: the tools the model has access to, the way those tools are wired up to do the work, and the structure that holds the whole pipeline together. The industry and practitioners have been trying to improve this for the past two years, and we have come a long way.
The discipline that has emerged in response is called harness engineering. If you spend any time on engineering social media, the phrase has probably started showing up in your feed. This piece is the version of the explanation I would give a friend who asked what the term means, why it matters, and where it came from. Some of those friends are technical, and some are not, but the argument is the same.

How we got here: three eras of building with LLMs
To understand why harness engineering became its own thing, it helps to look at the two failure modes that came before it.
The first era was prompt engineering, and it ran from roughly 2022 to 2024. The unit of work was the prompt itself. People wrote elaborate role-play scenarios (something like “you are an expert tax accountant, walk me through my deductions,” on the assumption that the framing would lift the quality of the answer), threaded chain-of-thought tricks (adding “let’s think step by step” before a hard question, or splitting a problem into parts and feeding each step’s output into the next prompt so the model could reason in stages instead of jumping to an answer), jailbroke models with cleverly worded preambles to get them to answer questions they had been trained to refuse, and shared “the perfect prompt” the way recipes get shared. Some of this was genuine craft, but a lot of it was, in Simon Willison’s phrase, “stupid hacks into a chatbot.” The unit of leverage was a single message, and you got better at it by writing more of them.
By the second half of 2024, anyone building a real product with an LLM had figured out that the prompt was just one slice of what the model actually saw. There was a system prompt, retrieved documents, tool definitions, conversation history, structured templates, and few-shot examples, and all of it competed for the same context window. The skill of getting the right things into that window started to look very different from the skill of writing a good prompt.
In June 2025, Andrej Karpathy posted a tweet endorsing a new term: context engineering. He defined it as “the delicate art and science of filling the context window with just the right information for the next step.” Tobi Lutke, Shopify’s CEO, gave it a sharper definition around the same time: “the art of providing all the context for the task to be plausibly solvable by the LLM.” The renaming caught on quickly, mostly because the practice it described was already what serious teams were doing, and they just did not have a clean name for it yet.
Then 2026 happened. Agents started to ship, and they did not ship as single calls to a model. They shipped as long-running processes that strung together dozens of steps, called tools, paged through memory, spawned subagents, and ran for hours. The context window was still important, but it was now one piece of a much bigger system, and the bigger system was where the failures lived. The agent would lose track of what it was supposed to do, get stuck in a loop editing the same file repeatedly, declare itself finished when half the work was still open, fabricate paths to files that did not exist, or watch a subagent drift away from the original goal across handoffs.
Harness engineering is the name people landed on for the discipline of designing that bigger system. Martin Fowler’s site called it “everything that wraps the model except the model itself,” OpenAI’s own engineering team published a piece on it, and over the following months Atlan, Augment, Firecrawl, Anthropic, Spotify, and Meta all started using the term in their own writing. By early 2026 it had circulated enough that you could use it with a larger part of the community without having to explain what it meant.
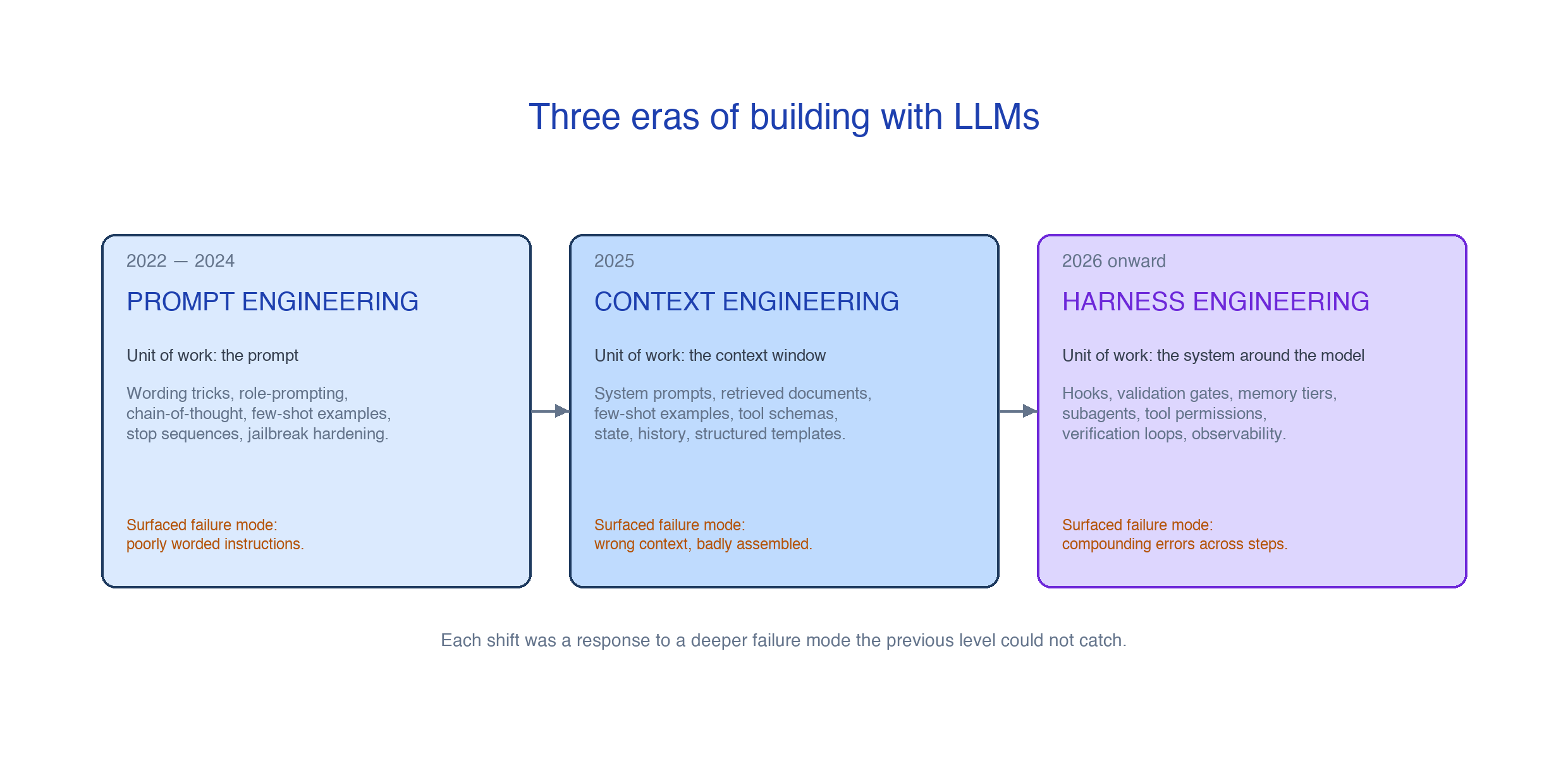
Each shift was a response to a deeper failure mode the previous level could not catch. Prompt engineering failed when the prompt was right but the context was wrong. Context engineering failed when the context was right but the orchestration of model calls around it was wrong. Harness engineering is what addresses that third layer.
What an agent harness actually is
Aparna Dhinakaran’s “What is an Agent Harness” is the formal definitional piece I have leaned on most while writing this, and her framing is what most of the field is building on right now. Her central distinction is that a harness is not a framework like LangChain or LangGraph that a human assembles into an agent, but an architecture that ships as a working agent and is designed for the model to accomplish almost any task with minimal human wiring. She lists nine canonical components; I am about to walk through six. The shorter list maps better to the teaching arc here, while her longer list covers pieces I am underweighting, including the iteration loop itself, sub-agent management, session persistence, and the permission layer as a separate first-class concern. If you want the full taxonomy after finishing this, her piece is the place.
For everyone else, the analogy that lands fastest is a kitchen.
A good chef can do impressive things on their own. Put one alone in an empty room with a single ingredient, and they will produce something memorable, eventually. Put the same chef in a real restaurant, and the work changes shape entirely. There is mise en place where ingredients are prepped to spec before service starts, recipes that codify what “done” looks like, timers that beep when something needs attention, sous-chefs who handle the work that does not need the head chef’s judgment, and an expediter who checks every plate before it leaves the line. None of that infrastructure exists because the chef is incompetent. It exists because reliable output at scale needs structure that does not depend on any single moment of attention.
The agent harness is the kitchen, and the model is the chef. The harness is everything you build around the model so the model can be reliably useful in production.
That includes a few specific pieces, and the easiest way to peel them open is one at a time.
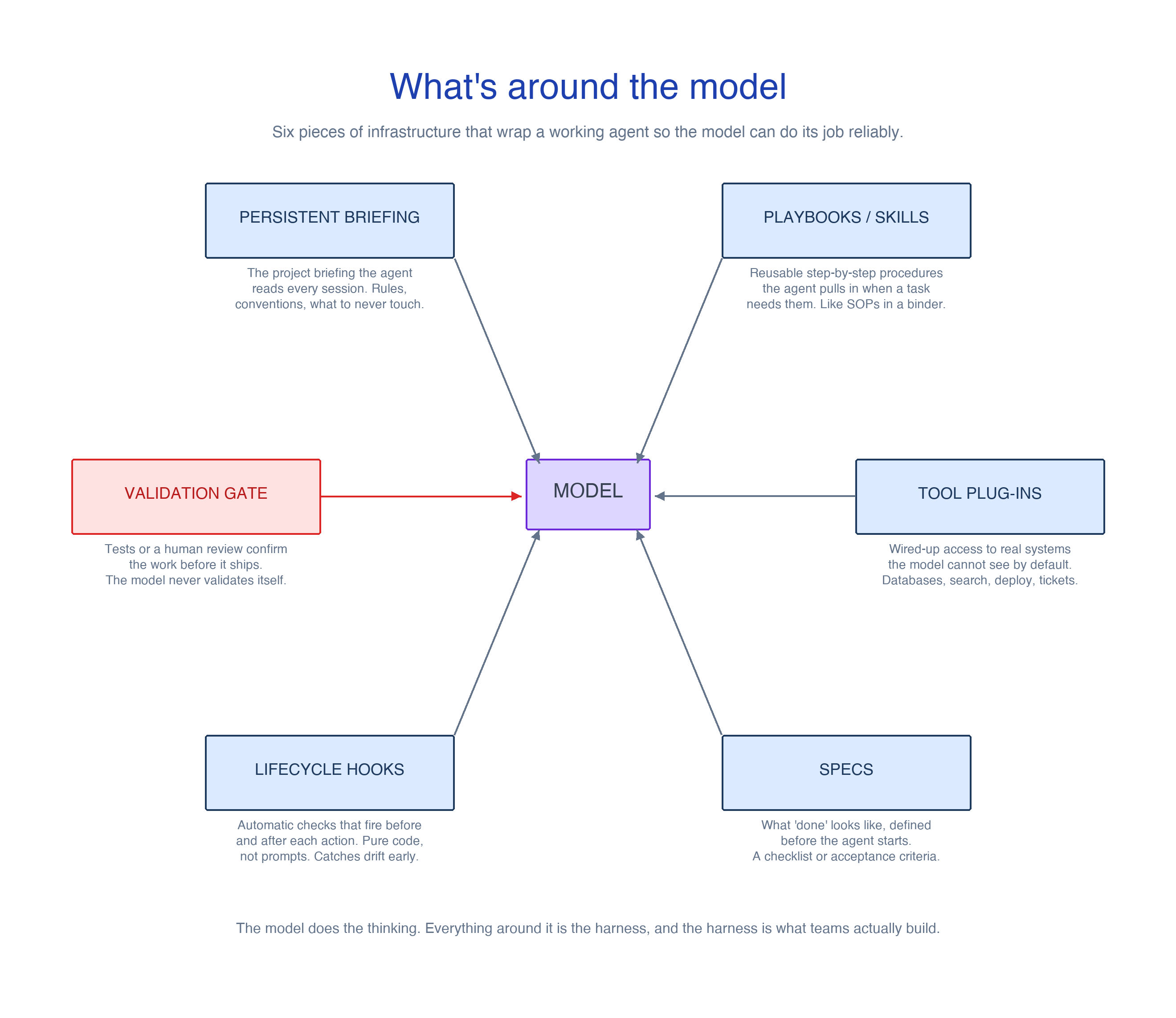
A persistent briefing. A document the agent reads at the start of every session. It defines what the project is, what the conventions are, what the rules are, and what the agent must never touch. In Anthropic’s Claude Code, this is the CLAUDE.md file, and in Cursor it is .cursor/rules. The pattern is the same: instead of re-explaining the project on every interaction, you encode the explanation once, and the agent reads it the way a contractor reads a project briefing on day one. It should be dense, specific, and kept current as the project changes shape.
Tool plug-ins. Most useful work involves systems the model cannot see by default, like a database, a deploy pipeline, a search index, or a ticketing system. The harness wires up access to those systems through structured tools, often via Model Context Protocol servers, sometimes via plain shell. The model does not have to remember how to query Postgres or commit to git, because those tools are wired in and described in a few lines each. Anthropic’s Claude Code, based on the leaked source code analysis, ships with under twenty default tools and activates more on demand. The lesson learned across multiple teams is that shorter tool lists outperform longer ones, because every tool description is a tax on the context window.
Skills, or playbooks. A skill is a packaged procedure the agent can load when a task calls for it. In Claude Code, skills live as directories with a description that stays in context and a body that loads only when triggered. Picture a binder of standard operating procedures: how to write a migration, how to review a pull request, how to run a postmortem. The agent pulls the relevant procedure off the shelf, follows it, and the procedure goes back on the shelf when the task ends. Skills make complex agents composable in the same way that functions make programs composable.
Specs. Before the agent does any work, the harness defines what done looks like. A spec might be a checklist, a structured template, a set of acceptance criteria, or a YAML schema with required fields. At MercadoLibre, Julián de Angelis is rolling out a spec-driven workflow across nearly twenty thousand developers and thousands of repositories. When the spec is rigorous before the agent runs, the output is reproducible across runs. When the spec is loose, the same task produces different results every time.
Lifecycle hooks. The hooks are deterministic actions that fire automatically at fixed points in the agent’s lifecycle, like before a tool runs, after a file is edited, when the working directory changes, or when the agent thinks it is done. They are pure code rather than prompts, and they run a formatter, validate a schema, count edits to a file, or refuse a dangerous command. Anthropic’s leaked source revealed twenty-five-plus hook points across Claude Code’s lifecycle. The principle behind all of them is consistent: do not trust the model to remember procedural invariants that have to hold every single time, because context pressure will eventually push those instructions out of mind. Encode the invariants in code that runs whether the model remembers or not.
A validation gate. This is the piece most teams underinvest in, and it is the one that does the most work to close the gap on the thirty-six percent problem. Before the agent declares the task complete, something other than the agent has to confirm, whether that is a test suite, a typed schema check, a second agent with a different role and a different system prompt, or a human review for high-stakes work. The validation lives outside the model because the model is biased toward its own first plausible answer. LangChain’s research on their own deep-agents harness was emphatic on this point, and forced verification before exit was one of the three changes that moved their benchmark fourteen points.
Memory. Long-running agents need a way to keep state across turns and sessions without drowning in their own context. Anthropic’s own approach in Claude Code is the cleanest version of the pattern that has emerged across the field. A small index, capped at around two hundred lines, stays in context permanently. Topic-specific files load on demand when the current task touches them. Full session transcripts live on disk and are searched only when needed. The agent navigates the layers with grep, ls, and glob, the same commands a senior engineer would use. There is no clever retrieval layer underneath any of this, just a filesystem and a handful of small Unix tools that compose well, and that turns out to be enough for most agent memory needs.
That is the harness, peeled open. None of the individual parts are particularly clever on their own, but a working agent usually needs all of them at once to make a successful production system.
Why this changes the math
Go back to the thirty-six percent problem. If your agent makes twenty independent decisions and each one is right ninety-five percent of the time, the chance of the whole thing being right end-to-end is 0.95 ^ 20, which is thirty-six percent. The problem gets worse fast: at ninety percent per step it falls to twelve percent, and at ninety-eight percent per step you keep sixty-seven percent.
The math has two implications worth sitting with for a minute.
The first is that no realistic improvement to the model alone will solve a twenty-step problem. Going from ninety-five to ninety-seven percent per step takes you from thirty-six percent to fifty-four percent end-to-end, which is not nothing, but it is also not “ship it” either. To get to ninety percent end-to-end success on twenty steps, you need ninety-nine and a half percent per step, which is a different category of problem than the model is solving.
The second implication is that almost everything inside a working harness is doing one of two jobs. Either it is reducing the chance of an error at a given step, through better tools, tighter specs, scoped instructions, and validation, or it is preventing an error at one step from cascading into the next, through hooks that intercept, subagents that isolate, and memory that gets reset. Once the math clicks, the harness components make a lot more sense as a coordinated response to a probability problem rather than a grab-bag of unrelated patterns.
This is also why eighty-eight percent of agent projects do not reach production, by recent industry estimates. The demos work, because demos are usually one or two steps. The production tasks have twenty steps, and the gap between the two is the harness. Most teams discover this only after they have shipped the demo and watched it fail in the wild.
The receipts
The most common pushback to a piece like this is that it sounds plausible in the abstract and falls apart on contact with real engineering. That is a fair concern, so here is the evidence trail with names and numbers attached.

LangChain published a detailed walkthrough of their work on deepagents-cli, an open-source coding agent harness. They held the model constant, fixing it to gpt-5.2-codex, and changed only the things around the model, including the system prompt, the tools, and the middleware. The harness moved from the middle of Terminal Bench 2.0 into the top five, and the headline number was a fourteen-point lift, from 52.8% to 66.5%, on a benchmark where most labs spend a quarter to move a single point. The three changes that mattered most were a verification middleware that re-evaluates the spec before the agent exits, a loop detector that intercepts the agent after it edits the same file too many times, and a reasoning budget that varies by phase, with high reasoning during planning and verification and lower reasoning during routine implementation.
OpenAI published their own harness piece in early 2026. Their internal engineering team used a Codex-based harness so heavily over five months that they wrote zero lines of application code by hand, and the agents wrote over one million lines through the harness. The harness was the leverage, and everything else, including the application code, was downstream of it.
Spotify’s Honk system has merged more than fifteen hundred AI-generated pull requests across hundreds of repositories since mid-2024. The harness around Honk includes verification loops, scoped permissions, and human review gates for anything touching production. The model in the loop has changed multiple times over those eighteen months, while the harness around it has stayed roughly stable.
Meta’s Ranking Engineer Agent is the most unusual architectural choice I have come across on this list so far. ML pipeline runs at Meta can take six hours, which is far longer than any agent’s context window can hold, so Meta’s harness uses hibernate-and-wake checkpointing where the agent serializes its state, suspends itself, and resumes from disk when the work is ready to continue. It is the agent equivalent of resuming a laptop from sleep, and none of the engineering involved has anything to do with the model itself.
Anthropic’s Claude Code is one of the most discussed production harnesses around, partly because its source leaked in April 2026. The patterns visible in the leaked code are now the reference architecture other teams cite, including tiered memory with a two-hundred-line index always in context, twenty-five-plus deterministic lifecycle hooks, typed and purpose-built tools instead of general shell, and subagents with their own context windows for research and planning. Every one of these is harness work rather than a model improvement.
The throughline across all five examples is the same: they use the same models everyone else can buy, and what is different is what they built around the models.
The Unix detour, and why it matters
There is a sub-story inside the harness story that deserves its own beat, because it is the place where engineering history shows up most clearly.
Two years ago, the assumption in the field was that long-running agents would need some elaborate retrieval layer to handle memory at scale, whether that meant vector databases, semantic search, or hybrid retrieval with reranking. Some of that is real for narrow use cases, but most of it has not held up for general agent memory. What has held up, somewhat surprisingly, is the filesystem itself.
Anthropic’s own documentation for Claude Code is the cleanest articulation of what replaced the indexing-and-embeddings stack. Claude Code does not pre-index your codebase, build embeddings, or maintain a vector store. It uses the filesystem directly, with Glob for finding files, Grep for content search, and Read for loading specific files into context as the agent needs them. Claude Code’s creator Boris Cherny said that in their own internal testing, agentic search “outperformed RAG by a lot, and this was surprising.” The same pattern shows up in Anthropic’s Memory tool, which persists memories as plain markdown files in a /memories directory, with no embeddings or vector database underneath. Cursor and Windsurf converged on the same primitives independently, and Arize’s Alyx extends the pattern further with hierarchical indexes on top of the filesystem.
If you want the longer treatment of this, Aparna’s piece on hierarchical memory in agent harnesses goes deeper than I do here and is worth reading after this.
The reason is practical. Agents are excellent at navigating filesystems because filesystem code is heavily represented in their training, and Unix commands compose, with each one doing one thing and the output of one becoming the input of the next. You do not have to design a retrieval API for every new question; you assemble a query plan on the fly with primitives the model already knows by heart.
What I find interesting about this pattern is that it is what data engineers have been doing for the past twenty years without bothering to name it. When you work in a warehouse like Snowflake, you do not pre-compute every answer a stakeholder might ask for; you write a query at the moment the question arrives, using a SELECT to choose columns, a WHERE that prunes the working set down to what actually matters, a JOIN that pulls in adjacent context, and an aggregation at the end. The query plan is assembled at runtime from small operators that compose, the data sits on cheap storage, and only the relevant slice gets pulled into compute. Anyone who has spent time tuning a dbt project has internalized this without thinking of it as a memory architecture, because we usually call it “good SQL.”
The agent harness pattern is the same instinct applied to language models. The filesystem plays the role of the warehouse, the Unix commands play the role of the operators, and the model plays the role of the compute layer that runs on whatever the operators returned. You do not load the world into context; you write a small query against it, run the query, and discard the intermediate result.
This is the part of the harness story I think will hold up the longest. The underlying principle is older than agents and shows up anywhere working memory is small but the data is large, which is to say almost everywhere in computing, and the agents are catching up to a discipline data engineers have been quietly running for years.
What this means if you are building
The mental shift, if you take this seriously, is from optimizing prompts to optimizing the system around prompts.
If you are technical, the implication is that your highest-leverage work for the next couple of years is probably not in the prompt or the choice of model. It is in your briefing files, your validation gates, your hooks, your tool design, and your memory layout. Those are specific to your product, your data, and your organization, which means they are also the only place a moat is likely to form. Anthropic, OpenAI, Google, and DeepSeek will keep shipping stronger checkpoints, and your competitors will see the same checkpoints on the same day you do, so there is not much advantage to be found at the model level. The advantage, if you can build one, is in what you wrap around the model.
If you are non-technical and you are watching this play out from the outside, the implication is that you should trust the teams who talk about the boring infrastructure more than the teams who talk about the magic of the model. The phrase “we built a clever prompt” should make you skeptical, while the phrase “we wired in a verification gate that catches premature exits” should make you lean in. The same is true when you are evaluating AI products: the product that visibly invests in checks, rollbacks, and human review is the one that is more likely to still be working a year from now.
There is also a compounding angle that is easy to miss but worth holding onto. A better briefing pays off on every run, until the project changes shape. A loop detector saves you an hour a week, every week. A good playbook turns a fuzzy task into a testable one every time you pull it off the shelf. None of these are one-off wins; they keep paying off, week after week, which is how leverage actually accumulates in this kind of work. Two years from now, the gap between teams that took the wrapping seriously early and teams that did not will probably look much wider than it does today, because every harness improvement compounds across every run.
The reframe
Next time your agent fails, try not to reach straight for a different model. The better question is: what failure pattern is this, and what structure would have caught it.
If the agent loses track of what it was doing, your briefing is probably wrong or too long. If the agent gives up at the first plausible answer, nothing is forcing it to verify. If the agent edits the same file ten times in a row, nothing is counting the edits. If the agent confidently fabricates a path that does not exist, your tools are too open and your permissions are too broad. Every one of those is a structural fix you can build, not a model upgrade you can buy.
The models have given us more than most of us expected three years ago, but they are not going to give us the rest for free. The rest is the briefing, the playbooks, the tools, the specs, the hooks, the validation gate, and the memory layout, and that is the part you actually have to build. The teams that took this seriously early are already the ones whose agents still work, and the gap between them and everyone else is going to keep widening.